

详解Python中迭代器和生成器的原理与使用


关于python中迭代器,生成器介绍的文章不算少数,有些写的也很透彻,但是更多的是碎片化的内容。本来可迭代对象、迭代器、生成器概念就很绕,又加上过于碎片的内容,更让人摸不着头脑。本篇尝试用系统的介绍三者的概念和关系,希望能够帮助需要的人。
1.可迭代对象、迭代器
1.1概念简介
迭代:
首先看迭代的字面意思:

迭代的意思就是:迭代是一种行为,反复执行的动作。在python中可以理解为反复取值的动作。
可迭代对象:顾名思义就是可以从里面迭代取值的对象,在python中容器类的数据结构都是可迭代对象,如列表,字典,集合,元组等。
迭代器:类似于从可迭代对象中取值的一种工具,严谨的说可以将可迭代对象中的值取出的对象。
1.2可迭代对象
在python中,容器类型的数据结构都是可迭代对象,列举如下:
- 列表
- 字典
- 元组
- 集合
- 字符串
>>> arr = ['圣僧','大圣','天蓬','卷帘'] >>> for i in arr: ... print(i) ... 圣僧 大圣 天蓬 卷帘 >>>
除了python自带的数据结构是可迭代对象之外,模块里的方法、自定义的类也可能是可迭代对象。那么如何确认一个对象是否为可迭代对象呢?有一个标准,那就是可迭代对象都有方法__iter__,凡是具有该方法的对象都是可迭代对象。
>>> dir(arr) ['__add__', '__class__', '__contains__', '__delattr__', '__delitem__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__getitem__', '__gt__', '__hash__', '__iadd__', '__imul__', '__init__', '__init_subclass__', '__iter__', '__le__', '__len__', '__lt__', '__mul__', '__ne__', '__new__', '__reduce__', '__reduce_ex__', '__repr__', '__reversed__', '__rmul__', '__setattr__', '__setitem__', '__sizeof__', '__str__', '__subclasshook__', 'append', 'clear', 'copy', 'count', 'extend', 'index', 'insert', 'pop', 'remove', 'reverse', 'sort']
1.3迭代器
常见迭代器是从可迭代对象创建而来。调用可迭代对象的__iter__方法就可以为该可迭代对象创建其专属迭代器。使用iter()方法也可以创建迭代器,iter()本质上就是调用可迭代对象的__iter__方法。
>>> arr = ['圣僧','大圣','天蓬','卷帘'] >>> arr_iter = iter(arr) >>> >>> for i in arr_iter: ... print(i) ... 圣僧 大圣 天蓬 卷帘 >>> >>> >>> arr_iter = iter(arr) >>> next(arr_iter) '圣僧' >>> next(arr_iter) '大圣' >>> next(arr_iter) '天蓬' >>> next(arr_iter) '卷帘' >>> next(arr_iter) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration
可迭代对象只能通过for循环来遍历,而迭代器除了可以通过for循环来遍历,重要的是还可以通过next()方法来迭代出元素。调用一次迭代出一个元素,直到所有元素都迭代完,抛出StopIteration错误。这个过程就像象棋中没有过河的小卒子——只能前进不能后退,并且迭代完所有元素也无法再次遍历。
简单总结迭代器的特征:
- 可以使用
next()方法迭代取值 - 迭代的过程只能向前不能后退
- 迭代器是一次性的,迭代完所有元素就无法再次遍历,需要再次遍历只有新建迭代器
迭代器对象在python中很常见,比如打开的文件就是一个迭代器、map,filter,reduce等高阶函数的返回也是迭代器。迭代器对象拥有两个方法:__iter__ 和__next__。next()方法能迭代出元素就是调用__next__来实现的。
>>> dir(arr_iter) ['__class__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__length_hint__', '__lt__', '__ne__', '__new__', '__next__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__setstate__', '__sizeof__', '__str__', '__subclasshook__']
1.4区分可迭代对象和迭代器
如何区分可迭代对象和迭代器呢?在python的数据类型增强模块collections中有可迭代对象和迭代器数据类型,通过isinstance类型比较即可区分出两者。
>>> from collections import Iterable, Iterator >>> arr = [1,2,3,4] >>> isinstance(arr, Iterable) True >>> isinstance(arr, Iterator) False >>> >>> >>> arr_iter = iter(arr) >>> isinstance(arr_iter, Iterable) True >>> isinstance(arr_iter, Iterator) True >>>
arr:可迭代对象。是可迭代对象类型,不是迭代器类型
arr_iter:迭代器。既是可迭代对象类型,又是迭代器类型
1.5可迭代对象和迭代器的关系
从迭代器的创建就能大致看出。可迭代对象就是一个集合,而迭代器就是为这个集合创建的迭代方法。迭代器迭代时是直接从可迭代对象集合里取值。可以用如下模型来理解两者之间的关系:
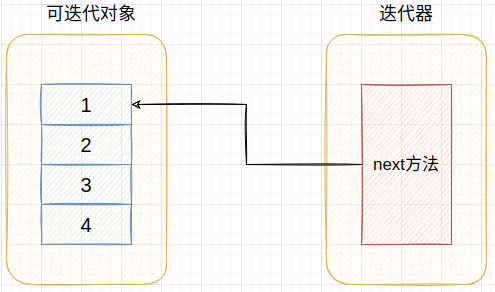
>>> arr = [1,2,3,4] >>> iter_arr = iter(arr) >>> >>> arr.append(100) >>> arr.append(200) >>> arr.append(300) >>> >>> for i in iter_arr: ... print(i) ... 1 2 3 4 100 200 300 >>>
可以看到这里的流程是:
- 先创建可迭代对象arr
- 然后从arr创建的arr_iter迭代器
- 再向arr列表追加元素
- 最后迭代出来的元素包括后追加的元素。
可以说明迭代器并不是copy了可迭代对象的元素,而是引用了可迭代对象的元素。在迭代取值时直接使用了可迭代对象的元素。
1.6可迭代对象和迭代器的工作机制
首先整理一下两者的方法
可迭代对象: 对象中有__iter__ 方法
迭代器:对象中有__iter__ 和 __next__方法
在迭代器的创建时提到过__iter__方法是返回一个迭代器,__next__是从元素中取值。所以,关于两者方法的功能:
可迭代对象:
__iter__方法的作用是返回一个迭代器
迭代器:
__iter__方法的作用是返回一个迭代器,就是自己。
__next__方法的作用是返回集合中下一个元素
可迭代对象是一个元素集合,本身没有自带取值的方法,可迭代对象就像老话说的茶壶里的饺子,有货倒不出。

>>> arr = [1,2,3,4] >>> >>> next(arr) Traceback (most recent call last): File "<stdin>", line 1, in <module> TypeError: 'list' object is not an iterator
既然饺子倒不出来,又想吃怎么办?那就得找筷子一样的工具来夹出来对吧。而迭代器就是给用来给可迭代对象取值的工具。
给可迭代对象arr创建的迭代器arr_iter,可以通过next取值,将arr中值全部迭代出来,直到没有元素抛出异常StopIteration
>>> arr_iter = iter(arr) >>> >>> next(arr_iter) 1 >>> next(arr_iter) 2 >>> next(arr_iter) 3 >>> next(arr_iter) 4 >>> next(arr_iter) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
for 循环本质
>>> arr = [1,2,3] >>> for i in arr: ... print(i) ... 1 2 3
以上通过for循环遍历出arr中所有值。我们知道列表arr是可迭代对象,本身无法取值,for循环如何迭代出所有元素呢?
for循环的本质就是给arr创建一个迭代器,然后不断调用next()方法取出元素,复制给变量i,直到没有元素抛出捕获StopIteration的异常,退出循环。可以通过模拟for循环更直观的说明:
arr = [1,2,3]
# 给arr生成一个迭代器
arr_iter = iter(arr)
while True:
try:
# 不断调用迭代器next方法,并捕获异常,然后退出
print(next(arr_iter))
except StopIteration:
break
>>
1
2
3
到这里大概就讲完了可迭代对象和迭代器的工作机制,简单总结:
可迭代对象: 保存元素,但自身无法取值。可以调用自己的__iter__方法创建一个专属迭代器来取值。
迭代器:拥有__next__方法,可以从指向的可迭代对象中取值。只能遍历一遍,并且只能前进不能后退。
1.7自己动手创建可迭代对象和迭代器
榴莲好不好吃,只有尝一尝才知道。迭代器好不好理解,动手实现一次就清楚。下面自定义可迭代对象和迭代器。
如果自定义一个可迭代对象,那么需要实现__iter__方法;
如果要自定义一个迭代器,那么就需要实现__iter__和__next__方法。
可迭代对象:实现__iter__方法,功能是调用该方法返回迭代器
迭代器:实现__iter__,功能是返回迭代器,也就是自身;实现__next__,功能是迭代取值直到抛出异常。
from collections import Iterable, Iterator
# 可迭代对象
class MyArr():
def __init__(self):
self.elements = [1,2,3]
# 返回一个迭代器,并将自己元素的引用传递给迭代器
def __iter__(self):
return MyArrIterator(self.elements)
# 迭代器
class MyArrIterator():
def __init__(self, elements):
self.index = 0
self.elements = elements
# 返回self,self就是实例化的对象,也就是调用者自己。
def __iter__(self):
return self
# 实现取值
def __next__(self):
# 迭代完所有元素抛出异常
if self.index >= len(self.elements):
raise StopIteration
value = self.elements[self.index]
self.index += 1
return value
arr = MyArr()
print(f'arr 是可迭代对象:{isinstance(arr, Iterable)}')
print(f'arr 是迭代器:{isinstance(arr, Iterator)}')
# 返回了迭代器
arr_iter = arr.__iter__()
print(f'arr_iter 是可迭代对象:{isinstance(arr_iter, Iterable)}')
print(f'arr_iter 是迭代器:{isinstance(arr_iter, Iterator)}')
print(next(arr_iter))
print(next(arr_iter))
print(next(arr_iter))
print(next(arr_iter))
结果:
arr 是可迭代对象:True
arr 是迭代器:False
arr_iter 是可迭代对象:True
arr_iter 是迭代器:True
1
2
3
Traceback (most recent call last):
File "myarr.py", line 40, in <module>
print(next(arr_iter))
File "myarr.py", line 23, in __next__
raise StopIteration
StopIteration
从这个列子就能清晰的认识可迭代对象的迭代器的实现。可迭代对象的__iter__方法返回值就是一个实例化的迭代器的对象。这个迭代器的对象保存了可迭代对象的元素的引用,也实现了取值的方法,所以可以通过next()方法取值。这是一个值得细品的代码,比如说有几个问题可以留给读者思考:
- 为什么next()只能前进不能后退
- 为什么迭代器只能遍历一次就失效
- 如果for循环的目标是迭代器,工作机制是怎样
1.8迭代器的优势
设计模式之迭代模式
迭代器的优势是:提供了一种通用不依赖索引的迭代取值方式
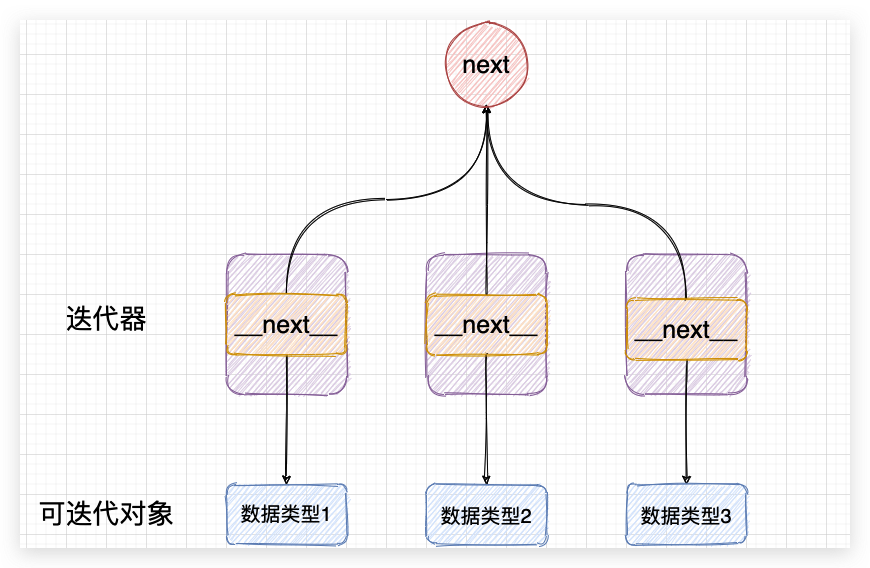
迭代器的设计来源于设计模式之迭代模式。迭代模式的思想是:提供一种方法顺序地访问一个容器中的元素,而又不需要暴露该对象的内部细节。
迭代模式具体到python的迭代器中就是能够将遍历序列的操作和序列底层相分离,提供一种通用的方法去遍历元素。
如列表、字典、集合、元组、字符串。这些数据结构的底层数据模型都不一样,但是同样都可以使用for循环来遍历。正是因为每一种数据结构都可以生成迭代器,都可以通过next()方法迭代,所以在使用的时候不需要关心元素的在底层如何保存,不需要考虑内部细节。
同样如果是自定的数据类型,即使是内部实现比较复杂,只需要实现迭代器,也就不需要关心复杂的结构,使用通用的next方法即可遍历元素。
复杂数据结构的通用取值实现
比如我们构造一个复杂的数据结构:{(x,x):value},一个字典,key是元组,value是数字。按照迭代的设计模式,实现通用取值方法。
例子实现:
class MyArrIterator():
def __init__(self):
self.index = 1
self.elements = {(1,1):100, (2,2):200, (3,3):300}
def __iter__(self):
return self
def __next__(self):
if self.index > len(self.elements):
raise StopIteration
value = self.elements[(self.index, self.index)]
self.index += 1
return value
arr_iter = MyArrIterator()
print(next(arr_iter))
print(next(arr_iter))
print(next(arr_iter))
print(next(arr_iter))
执行结果:
100
200
300
Traceback (most recent call last):
File "iter_two.py", line 22, in <module>
print(next(arr_iter))
File "iter_two.py", line 12, in __next__
raise StopIteration
StopIteration
只要实现了__next__方法就可以通过next()取值,不管数据结构多么复杂,__next__屏蔽了底层细节。这种设计思想是一个比较常见的思想,比如驱动设计,第三方平台介入设计等都是屏蔽差异,提供一个统一的调用方法。
1.9迭代器的缺点和误区
缺点
在上面的介绍中也提到了迭代器的缺点,集中说一下:
- 取值不够灵活。next方法只能往后取值,不能往前。取值不如按照索引的方式灵活,不能取指定的某一个值
- 无法预测迭代器的长度。迭代器通过next()方法取值,并不能提前知道要迭代出的个数
- 用完一次就失效
误区
迭代器的优势和缺点已经说的清晰了,现在讨论一个普遍对迭代器的一个误区:迭代器是不能节省内存的给这句话加一个前提:这里的迭代器是指普通的迭代器,而非生成器,因为生成器也是一种特殊的迭代器。
这可能是一个认识的误区,认为创建一个功能相同的可迭代对象和迭代器,迭代器的内存占用小于可迭代对象。例如:
>>> arr = [1,2,3,4] >>> arr_iter = iter([1,2,3,4]) >>> >>> arr.__sizeof__() 72 >>> arr_iter.__sizeof__() 32
咋一看确实是迭代器占用的内存小于可迭代对象,可仔细想一下迭代器的实现,它是引用了可迭代对象的元素,也就是说创建迭代器arr_iter同时也创建了一个列表[1,2,3,4],迭代器只是保存了列表的引用,所以迭代器的arr_iter实际的内存是[1,2,3,4] + 32= 72 + 32 = 104字节。
arr_iter本质上是一个类的对象,因为python变量是保存地址的特性,所以对象的的地址大小都是32字节。
后面有专门关于迭代器和生成器占用内存的分析,能够用数字来证明这个观点。
1.10python自带的迭代器工具itertools
迭代器在python占有重要的位置,所以python内置了迭代器功能模块itertools。itertools中所有的方法都是迭代器,可以使用next()取值。方法主要可以分为三类,分别是无限迭代器,有限迭代器,组合迭代器
无限迭代器count():创建一个无限的迭代器,类似于无限长度的列表,可以从中取值
有限迭代器chain():可以把多个可迭代对象组合起来,形成一个更大的迭代器
组合迭代器product():得到的是可迭代对象的笛卡儿积
关于更多itertools的使用可参考:Python中itertools模块的使用教程详解
2.生成器
生成器是一种特殊的迭代器,它既具有迭代器的功能:能够通过next方法迭代出元素,又有自己的特殊之处:节省内存。
2.1生成器的创建方法
生成器有两种创建方法,分别是:
()语法,将列表生成式的[]换成()就可以创建生成器- 使用
yield关键字将普通函数变成生成器函数
()语法
>>> gen = (i for i in range(3)) >>> type(gen) <class 'generator'> >>> from collections import Iterable,Iterator >>> >>> isinstance(gen, Iterable) True >>> isinstance(gen, Iterator) True >>>
>>> next(gen) 0 >>> next(gen) 1 >>> next(gen) 2 >>> next(gen) Traceback (most recent call last): File "<stdin>", line 1, in <module> StopIteration >>>
可以看到生成器符合迭代器的特征。
yield 关键字
yield是python的关键字,在函数中使用yield就能将普通函数变成生成器。函数中return是返回标识,代码执行到return就退出了。而代码执行到yield时也会返回yield后面的变量,但是程序只是暂停在当前位置,当再次运行程序时会从yield之后的部分开始执行。
from collections import Iterator,Iterable
def fun():
a = 1
yield a
b = 100
yield b
gen_fun = fun()
print(f'是可迭代对象:{isinstance(gen_fun, Iterable)}')
print(f'是迭代器:{isinstance(gen_fun, Iterator)}')
print(next(gen_fun))
print(next(gen_fun))
print(next(gen_fun))
执行结果:
是可迭代对象:True
是迭代器:True
1
100
Traceback (most recent call last):
File "gen_fun.py", line 17, in <module>
print(next(gen_fun))
StopIteration
执行第一个next()时,程序通过yield a返回了1,执行流程就暂停在这里。
执行第二个next()时,程序从上次暂停的地方开始运行,然后通过yield b返回了100,最后退出,程序结束。
yield的魔力就是能够记住执行位置,并且能够从执行位置再次执行下去。
2.2生成器方法
生成器既然是一种特殊的迭代器,那么是否具有迭代器对象的两个方法呢?查看两种生成器拥有的方法。
gen
>>> dir(gen) ['__class__', '__del__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__name__', '__ne__', '__new__', '__next__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'gi_yieldfrom', 'send', 'throw']
gen_fun
['__class__', '__del__', '__delattr__', '__dir__', '__doc__', '__eq__', '__format__', '__ge__', '__getattribute__', '__gt__', '__hash__', '__init__', '__init_subclass__', '__iter__', '__le__', '__lt__', '__name__', '__ne__', '__new__', '__next__', '__qualname__', '__reduce__', '__reduce_ex__', '__repr__', '__setattr__', '__sizeof__', '__str__', '__subclasshook__', 'close', 'gi_code', 'gi_frame', 'gi_running', 'gi_yieldfrom', 'send', 'throw']
两种生成器都有用迭代器的__iter__和__next__方法。
生成器是特殊的迭代器,想要区分出生成器和迭代器就不能使用collections的Iterator了。可以使用isgenerator方法:
>>> from inspect import isgenerator >>> arr_gen = (i for i in range(10)) >>> isgenerator(arr_gen) True >>> >>> arr = [i for i in range(10)] >>> isgenerator(arr) False >>>
2.3生成器的优势
生成器是一种特殊的迭代器,它的特殊之处就是它的优势:节省内存。从名字就可以看出,生成器,通过生成的方法来支持迭代取值。
节省内存原理:以遍历列表为例,列表元素按照某种算法推算出来,就可以在循环的过程中不断推算出后续的元素,这样就不必创建完整的列表,从而节省大量的空间。
以实现同样的的功能为例,迭代出集合中的元素。集合为:[1,2,3,4]
迭代器的做法:
- 首先生成一个可迭代对象,列表[1,2,3,4]
- 然后创建迭代器,从可迭代对象中通过next()取值
arr = [1,2,3,4] arr_iter = iter(arr) next(arr_iter) next(arr_iter) next(arr_iter) next(arr_iter)
生成器的做法:
- 创建一个生成器函数
- 通过next取值
def fun():
n = 1
while n <= 4:
yield n
n += 1
gen_fun = fun()
print(next(gen_fun))
print(next(gen_fun))
print(next(gen_fun))
print(next(gen_fun))
比较这两种方法,迭代器需要创建一个列表来完成迭代,而生成器只需要一个数字就可以完成迭代。在数据量小的情况下还不能体现这个优势,当数据量巨大时这个优势能展现的淋漓尽致。比如同样生成10w个数字,迭代器需要10w个元素的列表,而生成器只需要一个元素。当然就能节省内存。
生成器是一种以时间换空间的做法,迭代器是从已经在内存中创建好的集合中取值,所以消耗内存空间,而生成器只保存一个值,取一次值就计算一次,消耗cpu但节省内存空间。
2.4生成器应用场景
- 数据的数据规模巨大,内存消耗严重
- 数列有规律,但是依靠列表推导式描述不出来
- 协程。生成器和协程有着千丝万缕的联系
3.生成器节省内存、迭代器不节省内存
实践是检验真理的唯一标准,通过记录内存的变化来检测迭代器和生成器哪个能够节省内存。
环境:
系统:Linux deepin 20.2.1
内存:8G
python版本: 3.7.3
内存监控工具: free -b 以字节为单位的内存展示
方法:生成100万规模的列表,从0到100w,对比生成数据前后的内存变化
3.1可迭代对象
>>> arr = [i for i in range(1000000)] >>> >>> arr.__sizeof__() 8697440 >>>
第一次free -b在生成列表之前;第二次在生成列表之后。下同
ljk@work:~$ free -b
total used free shared buff/cache available
Mem: 7978999808 1424216064 2386350080 362094592 4168433664 5884121088
Swap: 0 0 0
ljk@work:~$ free -b
total used free shared buff/cache available
Mem: 7978999808 1464410112 2352287744 355803136 4162301952 5850210304
Swap: 0 0 0
现象:内存增加:从1424216064字节增加1464410112字节,增加 38.33 MB
3.2迭代器
>>> a = iter([i for i in range(1000000)]) >>> >>> a.__sizeof__() 32
ljk@work:~$ free -b
total used free shared buff/cache available
Mem: 7978999808 1430233088 2385924096 355160064 4162842624 5885038592
Swap: 0 0 0
ljk@work:~$ free -b
total used free shared buff/cache available
Mem: 7978999808 1469304832 2346835968 355160064 4162859008 5845966848
Swap: 0 0 0
现象:内存增加:从1430233088字节增加1469304832节,增加 37.26 MB
3.3生成器
>>> arr = (i for i in range(1000000)) >>> >>> arr.__sizeof__() 96 >>>
ljk@work:~$ free -b
total used free shared buff/cache available
Mem: 7978999808 1433968640 2373222400 362868736 4171808768 5873594368
Swap: 0 0 0
ljk@work:~$ free -b
total used free shared buff/cache available
Mem: 7978999808 1434963968 2378940416 356118528 4165095424 5879349248
Swap: 0 0 0
现象:内存增加:从1433968640字节增加1434963968节,增加 0.9492 MB
3.4小结
| - | 系统内存 | 变量内存 |
|---|---|---|
| 可迭代对象 | 38.33MB | 8.29MB |
| 迭代器 | 37.26MB | 32k |
| 生成器 | 0.9492MB | 96k |
以上结论经过多次实现,基本保存变量一致。从数据结果来看迭代器不能节省内存,生成器可以节省内存。生成100w规模的数据,迭代器的内存消耗是生成器的40倍左右,结果存在一定误差。
4.总结
可迭代对象:
属性:一种容器对象
特点:能够保存元素集合,自己无法实现迭代取值,在外界的帮助下可以迭代取值
特征:有__iter__方法
迭代器:
属性:一种工具对象
特点:可以实现迭代取值,取值的来源是可迭代对象保存的集合
特征:有__iter__ 和__next__方法
优点:实现通用的迭代方法
生成器:
属性:一种函数对象
特点:可以实现迭代取值,只保存一个值,通过计算返回迭代的下一个值。以计算换内存。
特征:有__iter__ 和__next__方法
优点:拥有迭代器特点同时能够节省内存
关于可迭代对象、迭代器、生成器的内容讲的比较多,不知道读者是不是已经云里雾里了?出道题检验一下:在文中使用的例子里西游记第一天团的人物名字是以谁的视角来称呼的?

